Voici une liste de formations Python orientées pour des besoins précis.
↧
[Inspyration] Formations Python
↧
[afpyro] AFPyro à Bruxelles (BE) - samedi 2 Février
Contexte
À l’occasion de la journée de conférences dans la salle python-devroom lors du FOSDEM, un AFPyro aura lieu avec un repas le samedi 2 Février.
Le détail du programme de la salle python-devroom: https://fosdem.org/2013/schedule/track/python/
Comment s’inscrire ?
Via ce formulaire: http://doodle.com/9k9bssgzsb4ebtk4
Quand ?
Le samedi 2 Février à partir de 19h.
- 18H40 : Rendez-vous devant la salle Ferrer, à coté du stand du FOSDEM.
- 19H00 : Arrivée au restaurant.
Où ?
↧
↧
[Biologeek] Routine et méditation
Lorsque je me suis engagé dans ma refonte avec un billet par jour, je n'étais pas sûr de pouvoir tenir (d'autant que j'avais déjà tenté l'expérience l'année précédente sans grand succès) et pour être tout à fait honnête certaines des étapes ont été pénibles à rédiger dans les temps. Par contre cela m'a permis de rentrer dans une routine d'écriture — dans une dynamique de partage — qui fonctionne bien jusqu'à présent.
Le fait de devoir me rendre à Montpellier régulièrement pour scopyleft y contribue également car j'ai choisi d'y aller de préférence en train pour ne pas « perdre » ce temps de trajet (et accessoirement produire moins de C02). Malgré les aléas du trafic, cela me laisse environ 1h30 par trajet aller-retour pour réfléchir, lire, écrire, en étant déconnecté. C'est un temps de transport en commun que j'appréciais énormément en étant à Paris (et un peu moins à Tokyo compte-tenu de la densité des rames) qui me permet de presser mon éponge pour me concentrer sur ce qui est important ou tout simplement de décompresser avant d'attaquer une journée de travail ou de rentrer.
Je ne l'ai jamais envisagé ainsi mais après avoir vu la vidéo de Andy Puddicombe, je me demande si je ne pourrais pas assimiler ces temps de transport à de la méditation, un moyen de mettre mes idées au clair. Pensez-y la prochaine fois, les trains ne sont pas en retard : la SNCF vous offre du temps de méditation en plus !
↧
[novapost] Introducing diecutter
Introduction
Some days ago we started a proof of concept about a template generation service called diecutter.
Today we are proud to present your the first release.
A lot of people didn't understand why we were so exited about this project.
Let me explain what is my feeling about it.
When you want to deploy a system or a project, you need to configure it for your environment it can be quite simple, just modify the settings.py of your django project for instance.
But if you want to keep it configured in you dev environment where you might be using sqlite3 as well as in production where you might want to use postgres then you will like diecutter.
Simple example of how we handle this
We create a config.ini file that will keep all our variables:
[admin] name = Webmaster email = webmaster@localhost [database] type = sqlite3 name = db.sqlite3
When you POST this config.ini file diecutter convert it to a context for your template:
{{ admin.name }}
{{ admin.email }}
{{ database.type }}
{{ database.name }}
Diecutter also add some information:
{{ diecutter.api_url }}
{{ diecutter.version }}
{{ diecutter.now }}
We create our template settings.py:
# Generated with diecutter-{{ diecutter.version }} at {{ diecutter.now }}
ADMINS = (
{% if admin %}('{{ admin.name }}', '{{ admin.email }}'),{% endif %}
)
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.{% if database and database.type %}{{ database.type }}{% else %}sqlite3{% endif %}',
'NAME': '{% if database and database.type %}{{ database.name }}{% else %}db.sqlite{% endif %}',
'USER': '{% if database and database.user %}{{ database.user }}{% endif %}',
'PASSWORD': '{% if database and database.passwd %}{{ database.passwd }}{% endif %}',
'HOST': '{% if database and database.host %}{{ database.host }}{% endif %}',
'PORT': '{% if database and database.port %}{{ database.port }}{% endif %}',
}
}
We store our new template in diecutter:
$ curl -XPUT http://localhost:8106/settings.py -F "file=settings.py"
And we can query our template:
$ curl -X POST --data-binary '@config.ini' -H "Content-Type: text/plain" http://localhost:8106/settings.py
# Generated with diecutter-0.1 at 2013-01-29 18:49:42.543776
ADMINS = (
('Webmaster', 'webmaster@localhost'),
)
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': 'db.sqlite3',
'USER': '',
'PASSWORD': '',
'HOST': '',
'PORT': '',
}
}
Going futher
The magic comes with the directory feature since you can configure all your app in one request with one config.ini file. All you components are then linked together with one file that is related to your environment.
More over you don't need to install anything in your host to configure it. So you can even configure the provisionning using diecutter.
↧
[hautefeuille] Application Bottle Python et Démon
Il est parfois utile de “daemoniser” rapidement une application Bottle Python. Les commandes proposées sont utiles pour des phases de développement. Il faudra se tourner vers des solutions plus industrielles pour la production.
Solution 1
Commande:
nohup python gateway.py &
Solution 2
Commande:
nohup python gateway.py > server.log &
Solution 3
Commande:
python -u gateway.py >> server.log &
Pour des solutions plus robustes
- Supervisord - http://supervisord.org/
- Creating a daemon the Python way (Python recipe) - http://code.activestate.com/recipes/278731-creating-a-daemon-the-python-way/
↧
↧
[raspberry-python] Applications pour téléphones mobiles avec Python
C'est une traduction de iPhone app with Python. J'ai eu une forte demande pour la version française.
Le programme lancé, on y voit un écran de démarrage, comme il se doit:
Mais c'est un programme web, et pas une application faite avec xcode.
Il suffit d'aller sur le lien de la galerie de Brython, ici:
gallery/geo.html et sur un iPhone, on l'ajoute a l'ecran d'accueil. On peut maintenant lancer le programme comme une vraie application iOS.
C'est bel et bien une application web, donc basée sur HTML et CSS, mais le code lui même, c'est écrit en Python. En plus, on utilise ici une toute nouvelle fonctionnalité de Brython, en faisant appel a un script Python externe a la page HTML (c'est une nouveauté qui date de cette fin de semaine), plutôt que d'avoir le code a même la page HTML. Cela nous permet une séparation de la présentation, de la logique et du "bling" (le CSS):
Application web pour iPhone typique, mais sans jQuery mobile ou autre module du genre. Et pas de onclick dans la page html. L'unique javascript c'est brython.js qui est l’interpréteur Brython même et l'appel a brython() par l'entremise de onload.
Le code Python n'est pas sur la page, mais on voit qu'on y fait reference par src="navi.py"
Allons donc voir ce qu'il y a dans ce fichier navi.py:
On établis 2 fonctions de rappel (callback). Une si on a notre géolocalisation (navi), et une s'il y a une erreur (nonavi), et finalement, une autre fonction (navirefresh) pour s'occuper de l’événement onclick du contrôle auto refresh dans la barre de menu de l'application. Le démarrage initial se fait par un appel a geo.getCurrentPosition avec nos fonctions de rappel. Ça fonctionne assez bien comme GPS.
Et si vous avez besoin d'aide, n'oubliez pas qu'il existe une liste en francais:
forum/brython-fr
@f_dion
Grâce a Brython
| L’icône Brython GPS |
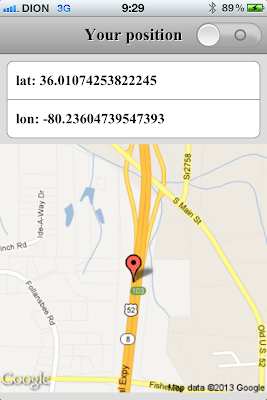
Une vraie app pour iPhone?
Le programme lancé, on y voit un écran de démarrage, comme il se doit:
 |
| Splash (ancienne carte de Caroline du Nord) |
Mais c'est un programme web, et pas une application faite avec xcode.
 |
| Le premier écran, mode manuel |
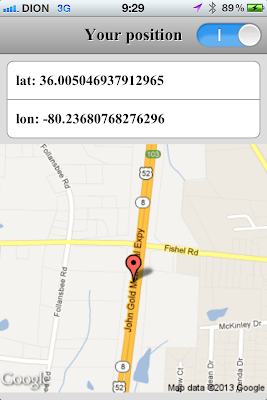 |
| Mode mise a jour automatique |
J'essaie?
Il suffit d'aller sur le lien de la galerie de Brython, ici:
gallery/geo.html et sur un iPhone, on l'ajoute a l'ecran d'accueil. On peut maintenant lancer le programme comme une vraie application iOS.
J'ai déjà vu cela, non?
C'est bel et bien une application web, donc basée sur HTML et CSS, mais le code lui même, c'est écrit en Python. En plus, on utilise ici une toute nouvelle fonctionnalité de Brython, en faisant appel a un script Python externe a la page HTML (c'est une nouveauté qui date de cette fin de semaine), plutôt que d'avoir le code a même la page HTML. Cela nous permet une séparation de la présentation, de la logique et du "bling" (le CSS):
Notre HTML
<!DOCTYPE html>
<html>
<head>
<title>Brython test</title>
<meta charset="iso-8859-1">
<meta name="viewport" content="user-scalable=no, width=device-width, initial-scale=1,maximum-scale=1">
<meta name="apple-mobile-web-app-capable" content="yes">
<script src="../brython.js"></script>
<script type="text/python" src="navi.py"></script>
<link rel="stylesheet" type="text/css" href="navi.css" />
<link rel="apple-touch-icon" href="icon.png"/>
<link rel="apple-touch-startup-image" href="splash.png">
</head>
<body onLoad="brython()">
<div id="header">
<H1>Votre position</H1>
<div id="switch">
<span class="thumb"></span>
<input id="refr" type="checkbox" />
</div>
</div>
</div>
<div id="navarea"></div>
<div id="maparea"></div>
</body>
</html>
Application web pour iPhone typique, mais sans jQuery mobile ou autre module du genre. Et pas de onclick dans la page html. L'unique javascript c'est brython.js qui est l’interpréteur Brython même et l'appel a brython() par l'entremise de onload.
Le code Python n'est pas sur la page, mais on voit qu'on y fait reference par src="navi.py"
Allons donc voir ce qu'il y a dans ce fichier navi.py:
Notre Python
# globals #########################
refr = False
geo = win.navigator.geolocation
watchid = 0
# les fonctions ###########################
def navi(pos):
xyz = pos.coords
ul = UL(id="nav")
ul <= LI('lat: %s' % xyz.latitude)
ul <= LI('lon: %s' % xyz.longitude)
mapurl = "http://maps.googleapis.com/maps/api/staticmap?markers=%f,%f&zoom=15&size=320x298&sensor=true" % (xyz.latitude, xyz.longitude)
img = IMG(src = mapurl, id = "map")
try:
doc["nav"].html = ul.html # on met a jour la liste
except KeyError:
doc["navarea"] <= ul # on cree la liste
try:
doc["map"].src = mapurl # on met a jour l'url de l'image
except KeyError:
doc["maparea"] <= img # on cree la balise img
def nonavi(error):
log(error)
def navirefresh(ev):
global refr, watchid
refr = False if refr else True
if refr == True:
doc["switch"].className = "switch on"
watchid = geo.watchPosition(navi, nonavi)
else:
doc["switch"].className = "switch"
geo.clearWatch(watchid)
# au demarrage ###########
if geo:
geo.getCurrentPosition(navi, nonavi)
doc["switch"].className = "switch"
doc["switch"].onclick = navirefresh # on associe un evenement onclick
else:
alert('geolocation not supported')
On établis 2 fonctions de rappel (callback). Une si on a notre géolocalisation (navi), et une s'il y a une erreur (nonavi), et finalement, une autre fonction (navirefresh) pour s'occuper de l’événement onclick du contrôle auto refresh dans la barre de menu de l'application. Le démarrage initial se fait par un appel a geo.getCurrentPosition avec nos fonctions de rappel. Ça fonctionne assez bien comme GPS.
Notre CSS
Le CSS étant un peu long, je ne le mettrai pas sur mon blog, mais vous pouvez trouver le code sur le site brython.info ou sur googlecode: SVN repository. Le CSS pour l'interrupteur genre ios 5 a ete emprunté ici: ios-5-style-switch-control.Ce n'est que le début
Alors voila, c'est un point de depart pour faire toute sortes de choses. Un tracker pour le jogging, le velo (avec local storage et synchro par appel ajax) et bien d'autres choses. Vous pouvez désormais faire tout cela avec votre langage favori (Python, bien sur) que ce soit pour votre téléphone mobile ou tablette. Cet exemple est quelque peu spécifique au iPhone (surtout a cause du CSS), mais fonctionne sur Android aussi et peut être adapté facilement aux tablettes. Et cela ne m'a pas pris beaucoup de temps.Et si vous avez besoin d'aide, n'oubliez pas qu'il existe une liste en francais:
forum/brython-fr
@f_dion
↧
[hautefeuille] Sonde de température Onewire, Arduino et visualisation OpenGL en Python
L’objectif de cette note est de réaliser un appareil capable de mesurer les températures, de transmettre ces données sans-fil à une station et enfin de réaliser un visualiseur de données en OpenGL.
Je vous conseille de lire une note précédente au sujet du capteur DS1821:
http://hautefeuille.eu/capteur-de-temperature-dallas-1821.html
Travail préparatoire
- Configurer les modules Xbee correctement,
- Conception physique et électrique.
Composants matériels
- Module Arduino,
- Sonde de température DS1821 avec sa résistance,
- Ecran LCD avec son module série (http://www.crystalfontz.com),
- 2 modules Xbee pour émission et réception
- Un convertisseur série vers usb pour un des modules Xbee.
Composants logiciels
- Arduino IDE
- Python 2.7.x
- Kivy (kivy.org)

Protocole d’échange sur le port série
J’ai décidé de formater mes paquets de données de la manière suivante:
$val1!val2!...*
Ce choix rend plus facile les manipulations ultérieures des données.
Code source Arduino
code:
#include <SoftwareSerial.h>
#include <OneWire.h>
// DS1821 on digital pin 2 external
OneWire ds(2);
// DS1821 on digital pin 8 internal
OneWire ds1(8);
// LCD on digital pin 6 et 7
SoftwareSerial LCD(6, 7);
// LCD on digital pin 6 et 7
SoftwareSerial XBEE(3, 4);
int led = 13;
void setup(void)
{
LCD.begin(9600);
XBEE.begin(57600);
Serial.begin(9600);
//start 1821 conversion external
ds.reset();
ds.write(0xEE);
//start 1821 conversion internal
ds1.reset();
ds1.write(0xEE);
pinMode(led, OUTPUT);
digitalWrite(led,LOW);
}
void loop(void){
// external _
// internal 1
byte temp_, temp1_;
byte present, present1;
// protocol
// $val0|val1|...*
// start packet
String paquet = "$";
digitalWrite(led,LOW);
delay(1000);
// Read value external
present = ds.reset();
ds.reset();
ds.write(0xAA);
temp_ = ds.read();
// Read value internal
present1 = ds1.reset();
ds1.reset();
ds1.write(0xAA);
temp1_ = ds1.read();
//start 1821 conversion external
ds.reset();
ds.write(0xEE);
//start 1821 conversion internal
ds1.reset();
ds1.write(0xEE);
// negative temp external
if (temp_ >> 7 == 1){
paquet = paquet + "E";
paquet = paquet + "!-";
paquet = paquet + ((temp_ ^ 0xFF) + 1); // bit inversion
}
// positive temp external
else
{
paquet = paquet + "E";
paquet = paquet + "!+";
paquet = paquet + temp_;
}
// negative temp internal
if (temp1_ >> 7 == 1){
paquet = paquet + "!I";
paquet = paquet + "!-";
paquet = paquet + ((temp1_ ^ 0xFF) + 1); // bit inversion
}
// positive temp internal
else
{
paquet = paquet + "!I";
paquet = paquet + "!+";
paquet = paquet + temp1_;
}
// closing packet
paquet = paquet + "*";
Serial.print(paquet);
LCD.print("?n");
LCD.print(paquet);
XBEE.print(paquet);
digitalWrite(led,HIGH);
delay(1000); // default 500
}
Code source Python pour le visualiseur
code:
# -*- coding: utf-8 -*-
"""
@author: julien@hautefeuille.eu
#sudo apt-get install python-kivy
Usage: viewerGL.py
"""
import kivy
kivy.require('1.5.1')
from kivy.app import App
from kivy.uix.label import Label
from kivy.uix.boxlayout import BoxLayout
from kivy.clock import Clock
import serial
class MeteoArduino(App):
title = 'Meteo Arduino'
def build(self):
layout = BoxLayout(
orientation='vertical',
spacing=10,
padding=10)
label_temp = Label(
text='',
font_size='60sp',
size_hint=(1, 0.5))
label_temp1 = Label(
text='',
font_size='60sp',
size_hint=(1, 0.5))
layout.add_widget(label_temp)
layout.add_widget(label_temp1)
def get_packet(obj):
data = ser.read(13)
if data.startswith("$") and data.endswith("*"):
clean = data.strip('$').strip('*').strip()
split = clean.split('!')
label_temp.text = split[1]
label_temp1.text = split[3]
print split
else:
pass
Clock.schedule_interval(get_packet, 1)
return layout
if __name__ == '__main__':
connection = '/dev/ttyUSB0'
ser = serial.Serial(connection, 9600)
MeteoArduino().run()
Dépôt du code source
↧
[Biologeek] Domain Driven Design et Python
J'ai eu le plaisir d'assister à une intervention de Paul dédié au Domain Driven Design (DDD) mis en application dans Qi4j qui était vraiment inspirante en terme de concepts.
Je me suis donc mis en quête de voir ce qui était possible en Python, je me souvenais de l'avoir vu mis en application par Olivier Girardot à travers sa présentation de l'architecture CQRS et performance avec Django et je pensais pouvoir trouver de nombreuses implémentations mais je suis clairement resté sur ma faim avec une présentation assez succincte liée à Flask dont le code est déjà plus intéressant avec la notion de contexte de stockage et de service d'authentification. Et puis pas grand chose d'autre en fait.
Pour aller plus loin, le livre Domain Driven Design Quickly semble être une bonne introduction et il a même été traduit en français (notez que le « Quickly » c'est quand même 88 pages…). Si vous avez d'autres ressources dans le domaine que l'on puisse utiliser dans un contexte Web et qui permette de modéliser des approches métier en Python, je suis preneur.
↧
[Biologeek] Écriture et navigateurs
Il y a une tendance ces derniers jours à proposer des options d'écriture dans le navigateur :
- Zen Writing Mode chez GitHub pour éviter les distractions ;
- ZenPen qui se rapproche de iA Writer avec une barre de défilement intéressante ;
- One line browser notepad et surtout ses commentaires qui ajoutent énormément de possibilités ;
- Writability inspiré de ce dernier auquel il manque le support de
localStorage(mais ça semble être problématique dans Chrome).
Je m'interroge, avec l'ajout des extensions JavaScript dans mon ContentBrowser, sur le fait d'en proposer une pour écrire — ou juste annoter — des articles afin de le transformer en un outil de lecture/écriture, à l'image de ce que devrait être le Web.
↧
↧
[raspberry-python] Nouvelle publication DIY
faitmain
Un nouveau magazine vient de paraitre, il s'agit de Fait Main, un magazine collaboratif en ligne et en PDF:http://www.faitmain.org
On y retrouve divers sujets autour du DIY("Do It Yourself"), et dans ce premier numéro, on y parle bien sur de Raspberry Pi.
J'ai écris l'article "câble d'interface pour Raspberry Pi" Lire l'article
Mais ce n'est pas tout:
Contenu du volume 1
La tribune de ce numéro est un parallèle entre web hébergé et OGM. Lire la tribuneLe premier article présente une application de reconnaissance de feuille écrite pendant un Hackathon. C'est l'application qui a été écrite en 24 heures par Olivier, Ronan & Tarek lors du dernier AngelHack à Paris. On y parle de machine-learning au service des plantes, des hackathons de programmation & de responsive design . Lire l'article
Le deuxième article parle de domotique et vous explique comment piloter des dispositifs sans fils - portails, détecteurs de mouvements etc. On y parle d' Arduino , de Raspberry-PI et de signal en 433 mhz . Lire l'article
Le troisième article présente le travail de Marcin Ignac: des méduses animées en 3D. Des captures d'écran de ces méduses ont ensuite été utilisées pour faire partie d'un projet de livre génératif. On y parle d' animation procédurale , de processing.js & d'hachurage. Lire l'article
Le quatrième article vous donne 5 conseils de photos culinaires pour que vous puissiez prendre en photos vos soupes, gigots et autres desserts comme un(e) pro. Lire l'article
Suit une interview de Hugues Aubin au LabFab de Rennes. Lire l'article .
Un cinquième article sur la conception d'un Juke box avec un Raspberry-PI, sans aucune soudure requise :) Lire l'article
Le sixième article vous explique comment recycler une vieille nappe de disque dur pour connecter le GPIO de votre Raspberry. Lire l'article
Le septième article est une rapide présentation du jeu The Midst , conçu avec Processing et WebPD. Lire l'article
Enfin, le huitième article aborde les bases du fonctionnement d'une CNC. Lire l'article
Bonne Lecture!
— Tarek
Equipe
Le projet FaitMain est monté par Tarek Ziadé mais est surtout possible grâce aux créateurs d'articles et aux relecteurs.Ont participé à ce numéro :
- Yannick Jost, Xavier Fernandez, Mathieu Agopian, Alexis Métaireau, Martine Cadot, Lina Ziadé - relectures
- Tarek Ziadé - Article "What The Feuille", Traduction "Cindermedusae", Article "Un Juke Box avec le Raspberry-Pi".
- Marcin Ignac - Article "Cindermedusae".
- Jonathan Schemoul - Article "Dispositifs sans fils"
- David Larlet - Tribune - "Semences stériles et données futiles"
- François Dion - Article "Cable d'interface pour Raspberry Pi"
- Brin de Cuisine - Article "5 petits trucs sur la photographie culinaire"
- Florian Strzelecki - Interview "Rencontre au LabFab de Rennes"
- Alcor Walter - Article "Le monde merveilleux des CNCs"
- Bérenger Recoules - Article "The Midst"
↧
[Biologeek] Communautés et jargon
— Le PO a écrit des US pourries, impossible de valider le DoD !
— C'était timeboxé, on n'a pas eu le temps de détailler le backlog avec le SM, ça ressortira lors du ROTI…
Je reviens des Agile Games France où j'ai passé 2 journées intéressantes dans une communauté qui m'est relativement étrangère. Suffisamment en tout cas pour me rendre compte à quel point le simple vocabulaire peut exclure le néophyte assez rapidement. Je prends la communauté agile mais j'ai bien conscience que n'importe quelle communauté a son propre jargon qui la différencie, qui l'identifie, qui sert de liant entre ses membres : on parle la même langue, on peut partager la même culture.
Je parlais récemment du Domain Driven Design qui a réglé le problème avec le language ubiquitaire — un glossaire métier partagé au sein de l'équipe —qui pourrait être mis en place dans les communautés. Encore faut-il vouloir intégrer de nouvelles personnes dans le groupe, ce qui n'est pas évident pour tous les membres et ce quelle que soit la communauté. Il est très intéressant d'identifier les mêmes patterns et les mêmes interrogations dans des communautés totalement différentes quant au rapports entre individus ou à la gestion de la croissance d'une communauté. Il y aurait beaucoup à écrire au sujet de l'éthologie humaine.
En discutant lors du retour de cela avec Vincent et Stéphane dans la voiture, on évoquait la possibilité de créer un glossaire métier dans nos projets avec scopyleft combinant notre vocabulaire avec celui du client et présentant un triple intérêt :
- la compréhension du métier en lui-même par l'équipe ;
- la compréhension de la concrétisation technique du produit par le client ;
- la compréhension par un nouvel arrivant sur le projet des termes clé employés pour décrire et être capable d'enrichir le projet.
Partagez-vous un vocabulaire commun avec vos interlocuteurs lors de vos projets web ? Si non, est-ce la source d'incompréhensions récurrentes ?
If in doubt that I communicated, I communicate again. Most issues in business occur because of simple miscommunications or the lack of communications.
Fabian Geyrhalter, Just Say No, and Other Lessons Learned from Running an Agency
Définir des outils et des cérémoniaux de communication au sein d'une équipe permet de faciliter la compréhension du projet par l'ensemble des personnes impliquées.
↧
[tarek] Launch of FaitMain.org

I am at the Fosdem in Bruxelles, trying to recover from last night beer event - and I should really be doing my slides for my talk, but I wanted to talk about my new personal project first: http://faitmain.org
Fait Main is a french online magazine I have started. It's in some ways very similar to Make : it contains articles about Raspberry Pi, Arduino, but also some topics around Python, Food, art in general, and some essays and interviews.
The link between all articles is the Do It Yourself approach, and we're trying for each article to present a projet that combines at least two topics of this list: eletronics, software, art, food & ecology.
The first issue was released a few days ago, and the next issue is planned in May.
In the first issue we're talking about CNC, Machine Learning, about Processing.js, Pure-Data and many other things.
The whole website is statically generated using Python & Mako & there's a Xapian-based search engine driven from Javascript.
Everyone is welcome to participate in the project at every level: coding, reviews, writing etc. Things are on Github at https://github.com/faitmain.
Content of the first issue :http://www.faitmain.org/auteurs/index.html
Oh I should mention: everything is in french ;)
↧
[alexis] Implementing CORS in Cornice
Note
I'm cross-posting on the mozilla services weblog. Since this is the first time we're doing that, I though it could be useful to point you there. Check it out and expect more technical articles there in the future.
For security reasons, it's not possible to do cross-domain requests. In other words, if you have a page served from the domain lolnet.org, it will not be possible for it to get data from notmyidea.org.
Well, it's possible, using tricks and techniques like JSONP, but that doesn't work all the time (see the section below). I remember myself doing some simple proxies on my domain server to be able to query other's API.
Thankfully, there is a nicer way to do this, namely, "Cross Origin Resource-Sharing", or CORS.
You want an icecream? Go ask your dad first.
If you want to use CORS, you need the API you're querying to support it; on the server side.
The HTTP server need to answer to the OPTIONS verb, and with the appropriate response headers.
OPTIONS is sent as what the authors of the spec call a "preflight request"; just before doing a request to the API, the User-Agent (the browser most of the time) asks the permission to the resource, with an OPTIONS call.
The server answers, and tell what is available and what isn't:

- 1a. The User-Agent, rather than doing the call directly, asks the server, the
API, the permission to do the request. It does so with the following headers:
- Access-Control-Request-Headers, contains the headers the User-Agent want to access.
- Access-Control-Request-Method contains the method the User-Agent want to access.
- 1b. The API answers what is authorized:
- Access-Control-Allow-Origin the origin that's accepted. Can be * or the domain name.
- Access-Control-Allow-Methods a list of allowed methods. This can be cached. Note than the request asks permission for one method and the server should return a list of accepted methods.
- Access-Allow-Headers a list of allowed headers, for all of the methods, since this can be cached as well.
- The User-Agent can do the "normal" request.
So, if you want to access the /icecream resource, and do a PUT there, you'll have the following flow:
> OPTIONS /icecream > Access-Control-Request-Methods = PUT > Origin: notmyidea.org < Access-Control-Allow-Origin = notmyidea.org < Access-Control-Allow-Methods = PUT,GET,DELETE 200 OK
You can see that we have an Origin Header in the request, as well as a Access-Control-Request-Methods. We're here asking if we have the right, as notmyidea.org, to do a PUT request on /icecream.
And the server tells us that we can do that, as well as GET and DELETE.
I'll not cover all the details of the CORS specification here, but bear in mind than with CORS, you can control what are the authorized methods, headers, origins, and if the client is allowed to send authentication information or not.
A word about security
CORS is not an answer for every cross-domain call you want to do, because you need to control the service you want to call. For instance, if you want to build a feed reader and access the feeds on different domains, you can be pretty much sure that the servers will not implement CORS, so you'll need to write a proxy yourself, to provide this.
Secondly, if misunderstood, CORS can be insecure, and cause problems. Because the rules apply when a client wants to do a request to a server, you need to be extra careful about who you're authorizing.
An incorrectly secured CORS server can be accessed by a malicious client very easily, bypassing network security. For instance, if you host a server on an intranet that is only available from behind a VPN but accepts every cross-origin call. A bad guy can inject javascript into the browser of a user who has access to your protected server and make calls to your service, which is probably not what you want.
How this is different from JSONP?
You may know the JSONP protocol. JSONP allows cross origin, but for a particular use case, and does have some drawbacks (for instance, it's not possible to do DELETEs or PUTs with JSONP).
JSONP exploits the fact that it is possible to get information from another domain when you are asking for javascript code, using the <script> element.
Exploiting the open policy for <script> elements, some pages use them to retrieve JavaScript code that operates on dynamically generated JSON-formatted data from other origins. This usage pattern is known as JSONP. Requests for JSONP retrieve not JSON, but arbitrary JavaScript code. They are evaluated by the JavaScript interpreter, not parsed by a JSON parser.
Using CORS in Cornice
Okay, things are hopefully clearer about CORS, let's see how we implemented it on the server-side.
Cornice is a toolkit that lets you define resources in python and takes care of the heavy lifting for you, so I wanted it to take care of the CORS support as well.
In Cornice, you define a service like this:
from cornice import Service
foobar = Service(name="foobar", path="/foobar")
# and then you do something with it
@foobar.get()
def get_foobar(request):
# do something with the request.
To add CORS support to this resource, you can go this way, with the cors_origins parameter:
foobar = Service(name='foobar', path='/foobar', cors_origins=('*',))
Ta-da! You have enabled CORS for your service. Be aware that you're authorizing anyone to query your server, that may not be what you want.
Of course, you can specify a list of origins you trust, and you don't need to stick with *, which means "authorize everyone".
Headers
You can define the headers you want to expose for the service:
foobar = Service(name='foobar', path='/foobar', cors_origins=('*',))
@foobar.get(cors_headers=('X-My-Header', 'Content-Type'))
def get_foobars_please(request):
return "some foobar for you"
I've done some testing and it wasn't working on Chrome because I wasn't handling the headers the right way (The missing one was Content-Type, that Chrome was asking for). With my first version of the implementation, I needed the service implementers to explicitely list all the headers that should be exposed. While this improves security, it can be frustrating while developing.
So I introduced an expose_all_headers flag, which is set to True by default, if the service supports CORS.
Cookies / Credentials
By default, the requests you do to your API endpoint don't include the credential information for security reasons. If you really want to do that, you need to enable it using the cors_credentials parameter. You can activate this one on a per-service basis or on a per-method basis.
Caching
When you do a preflight request, the information returned by the server can be cached by the User-Agent so that it's not redone before each actual call.
The caching period is defined by the server, using the Access-Control-Max-Age header. You can configure this timing using the cors_max_age parameter.
Simplifying the API
We have cors_headers, cors_enabled, cors_origins, cors_credentials, cors_max_age, cors_expose_all_headers … a fair number of parameters. If you want to have a specific CORS-policy for your services, that can be a bit tedious to pass these to your services all the time.
I introduced another way to pass the CORS policy, so you can do something like that:
policy = dict(enabled=False,
headers=('X-My-Header', 'Content-Type'),
origins=('*.notmyidea.org'),
credentials=True,
max_age=42)
foobar = Service(name='foobar', path='/foobar', cors_policy=policy)
Comparison with other implementations
I was curious to have a look at other implementations of CORS, in django for instance, and I found a gist about it.
Basically, this adds a middleware that adds the "rights" headers to the answer, depending on the request.
While this approach works, it's not implementing the specification completely. You need to add support for all the resources at once.
We can think about a nice way to implement this specifying a definition of what's supposed to be exposed via CORS and what shouldn't directly in your settings. In my opinion, CORS support should be handled at the service definition level, except for the list of authorized hosts. Otherwise, you don't know exactly what's going on when you look at the definition of the service.
Resources
There are a number of good resources that can be useful to you if you want to either understand how CORS works, or if you want to implement it yourself.
- http://enable-cors.org/ is useful to get started when you don't know anything about CORS.
- There is a W3C wiki page containing information that may be useful about clients, common pitfalls etc: http://www.w3.org/wiki/CORS_Enabled
- HTML5 rocks has a tutorial explaining how to implement CORS, with a nice section about the server-side.
- Be sure to have a look at the clients support-matrix for this feature.
- About security, check out this page
- If you want to have a look at the implementation code, check on github
Of course, the W3C specification is the best resource to rely on. This specification isn't hard to read, so you may want to go through it. Especially the "resource processing model" section
↧
↧
[Biologeek] Jardinier numérique
Si vous êtes un jardinier numérique, je vous encourage à reprendre le contrôle de vos semences^W^données afin de pérenniser votre récolte^W^identité numérique. Il n'est pas trop tard pour nourrir d'idées ouvertes et gratuites vos concitoyens du web.
J'ai écrit une tribune dans la droite lignée de mon billet Utopie et dystopie pour le premier numéro de Fait Main « un magazine en ligne conçu par des bénévoles passionnés par la bidouille en général » qui regroupe pour le lancement de son premier numéro des articles dédiés à l'informatique, l'électronique, la cuisine, l'art et l'écologie.
Je vous recommande la lecture de ce numéro ET la participation aux prochaines publications. Le plaisir artisanal de transmettre ce que l'on arrive à faire de ses mains est communicatif.
↧
[Biologeek] Conférences et auto-organisation
Voici quelques conseils relatifs à l'organisation de (un|a|non)-conférences car même si ce type de rassemblement ne demande pas une gestion d'orateurs ou d'éditorialisation des interventions, il n'en reste pas moins qu'il faut s'impliquer pour réussir un tel événement :
- présenter le format : que ce soit un barcamp, un open-space ou autre, chaque personne a sa propre implémentation du format et ce même parmi un auditoire aguerri donc prenez le temps de décrire les modalités d'auto-organisation que vous avez choisi ;
- accueillir les nouveaux : dans le cas d'une première édition, l'utilisation d'un ice-breaker permet d'établir un premier contact entre les participants, pour une seconde édition ce qui importe est davantage de mettre en avant les nouveaux venus et de faire en sorte qu'ils se présentent, voire qu'ils disposent d'un tuteur ;
- proposer les sujets : je suis de moins en moins pour des propositions sur une journée entière, je préfère connaître les sessions pour la demi-journée ou même moins de façon à garder la surprise et surtout être inspiré par les précédentes sessions pour en proposer, cela encourage également la participation des nouveaux ;
- tenir informés les participants : à la fois des salles, du contenu de la session en cours et du temps, ces 3 informations sont capitales et doivent être actualisées en permanence ;
- capitaliser sur les sessions : il est très compliqué de faire une restitution entre chaque session de ce qu'il s'est passé, d'autant qu'il faut vivre ces échanges ; par contre il est intéressant de pouvoir résumer en une phrase le bilan de la session avec 2/3 liens pour aller plus loin, à la fois pour les participants et pour ceux qui n'ont pas pu venir car « choisir, c'est bien souvent renoncer » dans ce type de format ;
- s'améliorer en continu : après 2/3 itérations ne pas hésiter à demander aux participants des pistes d'améliorations pour la suite (plus de salles, moins de sujets, des sessions plus courtes, des boissons, etc) ;
- faire des pauses : bien souvent les pauses correspondent aux changements de salles mais c'est trop court compte-tenu de l'intensité des sessions, il faut prendre le temps de discuter de manière informelle également et de reposer les cerveaux ;
- tenir la durée : tous les formats contributifs auxquels j'ai participé s'essoufflaient au bout d'un moment, par fatigue ou lassitude, ne pas hésiter à passer à autre chose pour terminer la journée : soit en plus passif avec des lightnings-talks ou en plus actif avec des jeux et/ou du code ;
- demander des retours : soit bien avant la fin de l'événement histoire d'avoir tout le monde comme cela a été fait avec la rétrospective lors des Agile Games, soit avec un peu de recul via un document collaboratif en ligne comme on le fait pour les rencontres Django.
Dans tous les cas, ne pensez pas qu'une conférence auto-organisée soit de tout repos pour les facilitateurs, c'est un exercice difficile qui demande des capacités d'écoute et de réactivité très développées.
↧
[cubicweb] Logilab's roadmap for CubicWeb as of February 2013
The Logilab team now holds a roadmap meeting every two months to plan its CubicWeb development effort. Here are the decisions that were taken on Feb 1st, 2013.
Version 3.17
This version should be published before the end of March and will finish all the things that are work in progress. It will include:
- the refactoring necessary to introduce persistant sessions,
- the shrinking of web/views: everything that does not deserve its own cube (like sioc, embed, geocoding, etc) will go into a cube named legacyui (this will open the door to squareui),
- stop serving pages with "content-type: application/xhtml",
- handling postgresql schemas (will require a new version of logilab.database),
- a new logo.
Squareui
Once the cube legacyui extracted (in version 3.17), it will be possible to move forward swiftly with squareui. Due to its other duties, one can not expect the core CW team to develop squareui. People interested will be in charge and ideally the squareui cube could be released when cubicweb 3.17 will be published.
Cleaning up the backlog
The lead CW developers will spend about 20% of their time cleaning up the ticket backlog at the forge (900 open tickets and 50 in progress !)
The first step will be to reduce the number of tickets "in progress", then to organize the open tickets and merge the duplicates.
Version 3.18
This version is due at the end of may 2013. It will include:
- persisting sessions,
- WSGI,
- RESTfulness: support for HTTP verbs PUT / DELETE, enforcement of the semantics of GET / POST (may be difficult to maintain backward-compatibility)
Mid-term goals
The mid-term goals are:
possibility to add new base types (Array, HStore, Geometry, TSVector, etc.) that would use extensions from the SQL backend
FROM clause in rql queries
websockets
defining attribute on relations and defining "virtual" relations or rules:
class Contribution(EntityType): author = SubjectRelation('Person', cardinality='1*', inlined=True) book = SubjectRelation('Book', cardinality='1*', inlined=True) role = SubjectRelation('Role', cardinality='1*', inlined=True) preface_writer = VirtualRelation('C is Contribution, C author S, C book O, ' 'C role R, R name "preface writer"')
And:
Any P WHERE B is Book, P preface_writer B
Will we need a materialized view in the database, a standard relation maintained by hooks, rewrite the RQL on-the-fly ? Time will tell.
cards with logic (mustache js templates for example)
coffeescript ? brython ? javascript ? prototype something with CubicDB + WebService that outputs json + user interface in full javascript
package separately Cubic(Web)DB et CubicWeb ?
think about the overall architecture (using WSGI, persistent sessions, etc.), and find solutions that fit a distributed architecture (look at paste.deploy, circus, etc.)
clean up the javascript en web/data/*.js
configurable metadata, managing the size of the entities table
more SPARQL
namespaces for the data models of the cubes
As already said on the mailing list, other developers and contributors are more than welcome to share their own goals in order to define a roadmap that best fits everyone's needs.
Logilab's next roadmap meeting will be held at the beginning of April 2013.
↧
[Inspyration] LFS : Sortie de la version 0.7.7
LFS est une solution e-commerce écrite en Python, un domaine ultra-dominé par les solutions PHP
↧
↧
[Inspyration] Django 1.5 : Sortie d'un livre en anglais
Two Scoops of Django, Best practices for Django 1.5, par Daniel Greenfeld et Audrey Roy
↧
[Inspyration] Fait Main : votre nouveau magazine
Voici une initiative rare et belle : un magazine libre en ligne avec du Python dedans
↧
[Inspyration] Pyo : Python et audio
Initiez-vous au traitement de signal sonore, la synthèse et la composition musicale algorithmique en Python grâce au module Pyo
↧